Attention in Transformers: concepts and code in PyTorch.
The main idea behind Transformers and Attentions
Transformers requires 3 main parts fundamentally: Word Embedding, Positional Encoding, and Attention, context aware embeddings.
-
Word Embedding converts words, bits of words and symbols, collectively called tokens, into numbers. (We need this because Transformers are a type of Neural Networks that only have numbers for input values.)
-
Positional Encoding helps keep track of word order.
-
Attention — self-attention(works by seeing how similar each word is to all of the words in the sentences, including itself)
-
Context aware embeddings can help cluster similar sentences and document
The Matrix Math for calculating self-attention

It is more common to use 512 or more numbers to represent each word.
Encoded values * Query weights(T) = Q
Encoded values * Key Weights(T) = K
Encoded values * Value Weights(T) = V
Dot products can be used as an unscaled measure of similarity between two things, and this metric is closely related to something called the Cosine Similarity. The big difference is that the Cosine Similarity scales the Dot Product to be between -1 to 1.
Square root of dk is the dimension of the Key matrix.
The percentages that come out of the softmax function tell us how much influence each word should have on the final encoding for any given word.
Coding self-attention in PyTorch
Import torch: Tensors are multidimensional lists optimized for neural networks.
import torch: for tensor operations.
import torch.nn: for the Module and Linear classes, and a bunch of other helper functions.
import torch.nn.functional: to access the softmax() function that we will use when calculating attention.
Define SelfAttention that inherits from nn.Module, which is the base class for all neural network modules that you make with PyTorch.
Create a __init__() method.
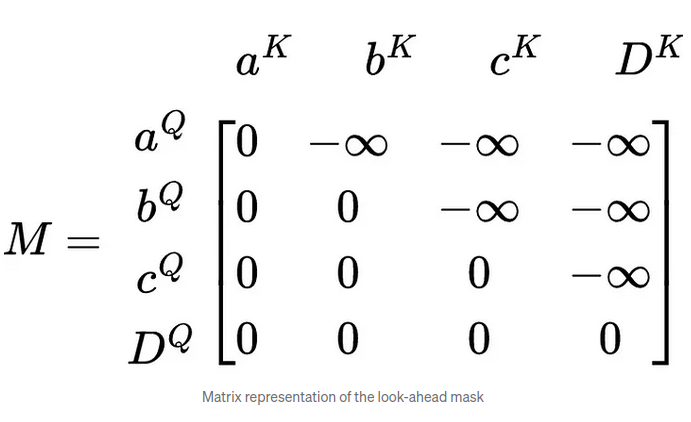
Self-attention vs Masked self-attention
Encoder-only transformer: Word embedding, positional encoding, self-attention, context-aware embeddings.
Decoder-only transformer: Word embedding, positional encoding, masked self-attention, generative inputs (e.g., ChatGPT).
Self-attention can look at words before and after the word of interest.
Masked self-attention ignores the words that come after the word of interest.
The matrix math for calculating masked self-attention
We add a new matrix, M for Mask, to the scaled similarities.
(The purpose of the mask is to prevent tokens from including anything that comes after them when calculating attention.)

coding masked self-attention in PyTorch
The forward() method is where we actually calculate the masked self-attention values for each token.
The True values correspond to attention values that we want to mask out.
encoder-decoder attention(cross-attention
It uses the output from the Encoder to calculate the keys and values.
The first Transformer was based on something called a Seq2Seq, or an Encoder-Decoder model.
multi-head attention
It uses the output from the Encoder to calculate the keys and values.
The first Transformer was based on something called a Seq2Seq, or an Encoder-Decoder model.
coding encoder-decoder attention and multi-head attention in PyTorch
import torch
import torch.nn as nn
# Define input parameters
embed_dim = 64 # Dimension of input embeddings
num_heads = 8 # Number of attention heads
seq_len = 10 # Sequence length
batch_size = 32 # Batch size
# Create Multihead Attention layer
mha = nn.MultiheadAttention(embed_dim=embed_dim, num_heads=num_heads, batch_first=True)
# Random input tensor (batch_size, seq_len, embed_dim)
query = torch.rand(batch_size, seq_len, embed_dim)
key = torch.rand(batch_size, seq_len, embed_dim)
value = torch.rand(batch_size, seq_len, embed_dim)
# Apply multi-head attention
output, attn_weights = mha(query, key, value)
print(output.shape) # Output: (batch_size, seq_len, embed_dim)
print(attn_weights.shape) # Attention weights: (batch_size, num_heads, seq_len, seq_len)
Reference:
Deep learning from Professor Andrew Ng